

In his opening remarks during this past September’s Senate Commerce Committee hearing examining privacy policies of top tech and telecommunications firms, Senator John Thune stated, “The question is no longer whether we need a federal law to protect consumers’ privacy. The question is what shape it should take.”
While Europe’s implementation of GDPR and California’s passage of the CCPA framed these remarks, the intervening months have only seen increased calls for national privacy legislation from public interest groups and a host of privacy proposals from policymakers ranging from prison terms for tech executives to less controversial approaches.
Speaking at the hearing in September, Sen. Thune seemed to describe the current moment well:
We have arrived at a moment where, I believe, there is a strong desire by both Republicans and Democrats, and by both industry and public interest groups, to work in good faith to reach a consensus on a national consumer data privacy law that will help consumers, promote innovation, reward organizations with little to hide, and force shady practitioners to clean up their act.
This is not without reason. Several high profile stories broke in 2018 that have given many people pause about how data is collected, protected, and shared.
There’s just one problem underlying the momentum building for national privacy regulation: The push for regulatory intervention in data privacy rests primarily on the assumption of market failure. Instead, clear identification and articulation of a market failure is a first step in investigating whether and how to regulate. Moreover, we need to determine if the market failures we are identifying rise to the level of warranting a federal regulatory intervention.
While many have leapfrogged this necessary step in the regulatory process, I want to outline some considerations we ought to make before settling on any national data privacy regulation.
What is Privacy?
Any conversation about the public enforcement of privacy must necessarily begin with a clear understanding of what we mean. It is vital that we not take this concept as a given. Unfortunately, for many, the concept of privacy is both complicated and convoluted. Here’s how one of the world’s foremost privacy experts, Daniel Solove, opens his book on the subject:
When I first began exploring privacy issues, I sought to reach a definitive conclusion about what “privacy” is, but after delving into the question, I was humbled by it. I could not reach a satisfactory answer. This struggle ultimately made me recognize that privacy is a plurality of different things and that the quest for a singular essence of privacy leads to a dead end.
While there may be legal and philosophical complexities in defining privacy, economists have been defining it in far more blunt and specific terms. Given their simplicity, the economic understanding of privacy is a solid foundation for the current debates over data collection and use. This perspective is even more important given that privacy regulation, above all else, is economic regulation.
In one of the earliest economic examinations of privacy, Posner (1977) defined privacy simply as “the withholding or concealment of information.” Writing a few years later, Stigler (1980) defined it as “the restriction of the collection or use of information about a person or corporation.” Although four decades of research has built and expanded on their work, from these definitions, we can outline a few characteristics that may help illuminate where current data privacy practices are falling short.
First, privacy exists in the context of our relationships with others. As Neil Chilson recently explained, the concept only makes sense with respect to more than one party. In this way, according to Chilson, privacy has three primary components:
Entity A, information about Entity A, and Entity B. The less information about A that B can perceive and use, the more privacy A has from B.
Second, from an economic perspective, these relationships are primarily transactional. Yes, there are other considerations (perhaps modesty, for example). But privacy is best understood as an intermediate good. That is, individuals do not seek privacy as an end. Instead, data collection and concealment are done primarily for economic reasons, and the primary function of privacy is economic gain.
Third, given the economic nature of privacy, any discussion surrounding privacy regulation must necessarily involve a discussion of economic harms. Harms can take a number of different forms. Although, as my coauthors and I have pointed out, harm in a data security context is difficult to both define and identify.
Market Failures and Data Privacy
With a baseline definition of privacy, we can begin to examine where market failures may exist in data privacy. In particular, externalities and asymmetric information are the primary justifications used to advance regulations around privacy.
Most of the major policy proposals, for example, either directly or indirectly discuss the concepts. Senator Mark Warner outlined some proposed paths and specifically mentions the idea of asymmetries. Senator Brian Schatz’s Data Care Act of 2018 creates a duty of loyalty for tech companies that prohibits them from imposing externalities (although the bill doesn’t call them that). It seems natural, then, to focus on these concepts and how they fit in discussions of data privacy.
Before digging in, however, it seems worthwhile to provide some definition for what constitutes a market failure. Simply put, a market failure occurs when “competitive conditions are not met and markets fail to allocate resources efficiently.” In the context of data privacy, the mere existence of asymmetric information and externalities is not enough to justify a claim of market failure. I’ll explain below.
Externalities
In economics, externalities occur when actions by one party impose uncompensated costs (or benefits) on another party. In Eli Dourado’s article on cybersecurity market failures, he provides a simple example of externalities to get us started:
Consider fans at a baseball stadium. A player hits a ball deep into the outfield, and the fans are eager to see if it will be a home run. To get a better view, one fan stands up. This worsens the view of the fan seated directly behind him. That fan also stands up for a better view, as does the fan in the next row, and so on. In equilibrium, we will observe all the fans standing up, each with a view no better than if he or she were seated. If we assume that, other things equal, fans prefer to sit than to stand, then we can infer a market failure. Fans would be better off if they could agree not to stand to get a better view during the exciting moments of the game. The market failure is driven by the externality: the deterioration of the seated fans’ view when some fans stand up.
In this example, the choice by some fans to stand imposes uncompensated costs on other fans. In the same way, we can think through externalities in data privacy; Those include those instances in which the use of data by one party imposes a cost on another. However, their reciprocal nature, the mere existence of externalities does not establish the presence of market failure. Nobel Laureate Ronald Coase (not talking about data privacy) explained why:
The question is commonly thought of as one in which A inflicts harm on B and what has to be decided is: how should we restrain A? But this is wrong. We are dealing with a problem of a reciprocal nature. To avoid the harm to B would inflict harm on A. The real question that has to be decided is: should A be allowed to harm B or should B be allowed to harm A? The problem is to avoid the more serious harm. If by inflicting $5 of harm on A, B gains $10, then it is efficient for B to continue to harm A. For if B were prohibited from harming A, he would lose $10, while A would gain only $5. Society as a whole is better off if B harms A than if A harms B. The problem is to avoid the more serious harm.
Back at the baseball game, the choice is clear: stand or sit. The answer, however, isn’t. As Coase explains: “What answer should be given is, of course, not clear unless we know the value of what is obtained as well as the value of what is sacrificed to obtain it.”
Now, let’s assume that (1) B has acquired information about A, (2) B may use or share this data (in compliance with existing laws, regulations, and contractual obligations), and (3) A feels that the use of the data will harm her. Should B be prohibited from using the data?
The Data Care Act, for example, provides one answer to that question:
An online service provider may not use individual identifying data, or data derived from individual identifying data, in any way that —
(A) will benefit the online service provider to the detriment of an end user; and
(B)(i) will result in reasonably foreseeable and material physical or financial harm to an end user;
However, from a Coasian perspective, it isn’t that easy. The answer requires information (or assumptions) about who is harmed, which harm is greater (or ought to be avoided), and who is in the best position to avoid the harm. Simply instituting a rule that B cannot use or share the data about A assumes that these answers will remain the same in every context; moreover, it assumes that this cannot be resolved through private ordering and contracts (i.e., that regulation is required in the first place).
Asymmetric Information
However, for transactions surrounding B’s use of A’s data to occur, both A and B need to have adequate information to make informed choices (not perfect information, but a sufficient amount). This is where the second putative market failure is typically identified and used as a basis for regulation.
Sen. Warner, in his white paper outlining data privacy regulation, states that “numerous studies indicate users have no idea their information is being used in this manner, resulting in a massive informational asymmetry.” Many people question whether consumers are even in a position to make the types of Coasian bargains with platforms that may occur in the example given above. Instead, consumers are alleged to be ignorant of the amount of information collected and how it will be used. As a result, consumers agree to an over-collection of data relative to what would occur if they had complete information.
While it’s true that consumers seem to do very little to educate themselves about a platform’s policies (one study, for example, found that users seldom consulted privacy policies and have inaccurate perceptions of their knowledge about privacy technology and vulnerabilities), it might not seem to matter. Alan McQuinn at ITIF explains why:
However, recent studies suggest that consumer behavior is not influenced by whether they read privacy notices. Ben-Shahar and Chilton (2016) analyzed how participants would behave based on the privacy policy of a dating app, where one policy explained that the app would collect highly sensitive information, such as sexual history, and sell that information to third-party advertisers. The authors found that consumers’ willingness to share this information was the same, regardless of what the privacy policy said and whether the participants had read it. Even when people understood the privacy policy and the information was highly sensitive, they still chose to share it. In part this may be because they believe that they would receive some benefit from sharing which would outweigh the risk from that sharing.
In truth, it seems that consumers have a pretty good idea that their personal information is being collected but seem to value it less than what they’re getting in exchange from the platforms. A recent article the Harvard Business Review provides a nice way to visualize how consumers value different data. At a glance, it’s clear that consumers’ willing to pay for privacy is pretty low for most data collected by private companies.
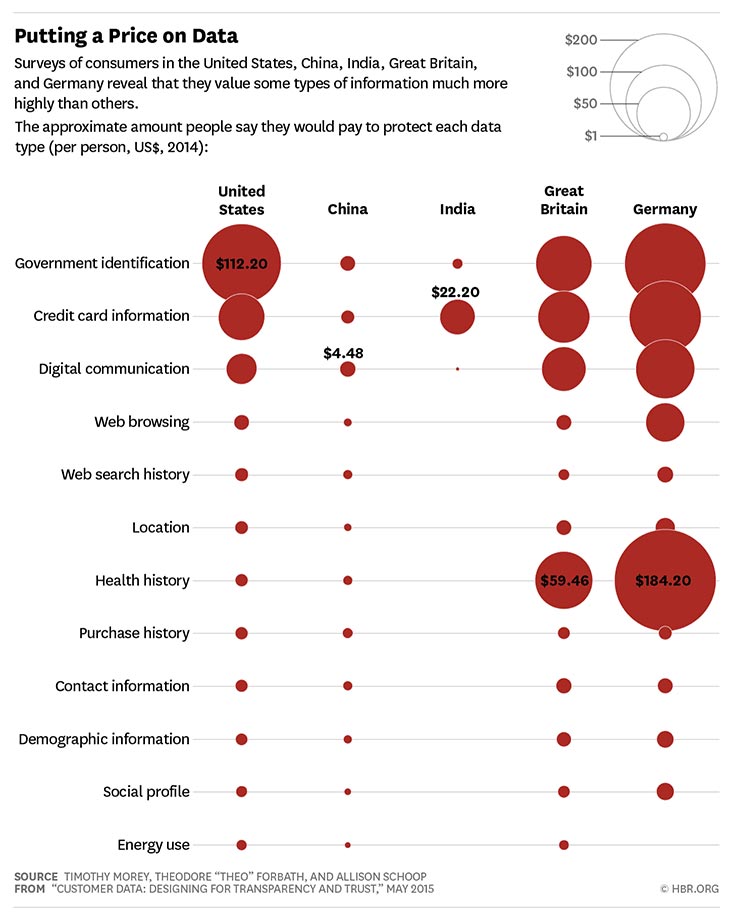
Using unique data from one of the largest privacy surveys ever conducted, Caleb Fuller seems to confirm this. Specifically asking respondents about their Google use, Fuller finds that:
- 90% of respondents are aware of Google’s information collection;
- 15% of Google users would be willing to pay to avoid tracking; and
- The average annual willingness to pay to have privacy on Google was $76.78.
While $77 seems like a significant amount, as Fuller explains:
100% of my respondents indicate they use Google at least once daily. This suggests that respondents would be willing, on average, to pay about 21 cents daily for privacy on Google. A per search measure would clearly be even lower.
In short, according to Fuller, consumers are well-informed about tech companies’ privacy practices, but they place little value on additional privacy. This seems to suggest that information asymmetries are over-exaggerated.
Conclusion
The point here isn’t to declare one way or another if there are systemic market failures in data privacy. While there are surely identifiable externalities and information asymmetries, there are also a number of potential solutions outside a federal regulatory response. Each perceived market failure should be clearly articulated, the responses (both private and public) evaluated, and conclusions drawn from facts and data. As Posner (1978) explained long before today’s privacy debates, “Discussions of the privacy question have contained a high degree of cant, sloganeering, emotion, and loose thinking.”
Grounding today’s discussion in sound economic analysis may go a long way to proving Posner wrong on that.
Thanks to The Center for Growth and Opportunity, Megan Hansen, and Josh T. Smith.